
Python is a powerful programming language. And there is so much we can do with it to make the code lighter and faster. It not only supports features like multiprocessing but does it with ease. Below, we’ve listed some of the best Python code optimization tips and tricks. Since Python is a feature-rich language, there’s always scope for improvement. If you wish to make your Python code run even faster and more efficiently, then continue reading.
The beauty of these tips and Python is all optimization techniques actually, lie within the realm of Python. You just need to know them and implement them in a disciplined approach while coding. Recently, we’d written an article on thirty Python tips and tricks. You can check it out as well to find what you don’t know already.
Python Code Optimization Tips and Tricks for Geeks

Let’s first begin with some of the core internals of Python that you can exploit to your advantage.
1. Interning Strings for Efficiency
Interning a string is a method of storing only a single copy of each distinct string. And, we can make the Python interpreter reuse strings by manipulating our code to trigger the interning of strings.
Usually, when we create a string object, it’s up to the Python interpreter to determine whether or not to cache the string. It’s the inherent nature of the interpreter that it reveals in certain conditions like while processing the identifiers.
Declaring a string with a name that starts either with a letter or an underscore and includes only combinations of letters/underscores/numbers, will make Python intern the string and create a hash for it.
Since Python has a lot of internal code using dictionaries, which leads it to perform a number of searches for identifiers. So interning the identifier strings speeds up the whole process. To put it simply, Python keeps all identifiers in a table and generates unique keys (hash) per object for future lookups. This optimization takes place during compilation. And, it also combines the interning of string literals that resembles the identifiers.
So it’s quite a useful feature in Python that you can exploit to your benefit. Such a feature can help you speed up the processing of a large text mining or analytics application. Because they require frequent searches and flip-flops of messages for bookkeeping.
The strings that you read from a file or receive through a network communication aren’t part of the auto-interning in Python. Instead, you can offload this task to the intern() function for handling such strings.
2. Peephole Optimization technique
Peephole optimization is a method that optimizes a small segment of instructions from a program or a section of the program. This segment is then known as <Peephole> or <Window>. It helps in spotting the instructions that you can replace with a minified version.
Let’s see how Python deals with peephole optimization. It has a built-in way of doing it, check out the examples below.
Example-1
The example has a function initializing two of its members. One of them is a string whereas another one is an integer. Following next is one more code attribute that gets added to the function and will default to <None>. The interesting part is that the four literal(s) will linger in memory as constants. Please refer to the image given below.
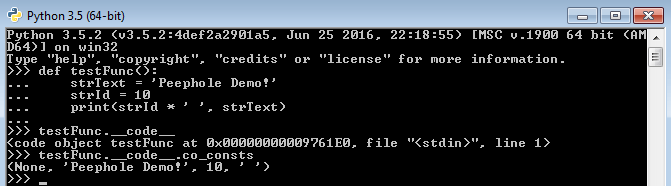
In the attached snapshot, you can see that we’ve used the constant <.__code__.co_consts>. It is one of the three tuples that every function object in Python has. Yes, a function is also an object in Python. It comprises the following three tuples.
1. The <__code__.co_varnames>: Holds local variables including parameters.
2. The <__code__.co_names>: Stores global literals.
3. The <__code__.co_consts>: References to all the constants.
Now, there is more that the peephole optimization can do like turning mutable constructs into immutable. Refer to the below examples.
Example-2
In this example, we are searching for a particular element in a set using the “in” operator. Here, Python will detect that the set is going to be used to verify the membership of an element. So it’ll treat the instructions as a constant cost operation irrespective of the size of the set. And will process them faster than it would have done in the case of a tuple or a list. This method is known as membership testing in Python. Kindly check the attached screenshot.

Example-3
Nonetheless, if you do use the list object in a similar fashion as we did with the set in the last example, then Python will translate it into a tuple constant. Now, in this example, we’ve clubbed the usage of both the set and list together. And shown that both objects are getting translated into constants. Please refer to the attached screenshot.

In the same fact, we can verify this by looking at the bytecode of the translated code. For this purpose, we have to import Python’s “dis” module. Passing the function object as an argument to the “dis” constructor will print the entire memory layout in bytecode.
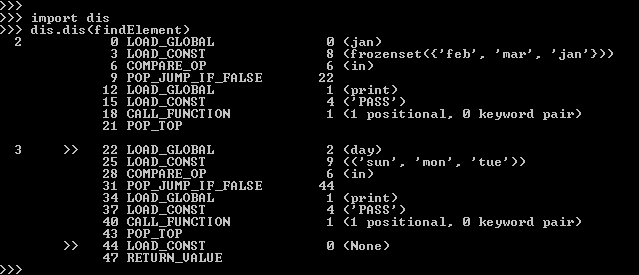
From the “dis” output in the attached image, it’s quite easy to verify that both the set and list have turned as Constants.
3. Profile your code
Before you further dive into optimizing your code, it would be naive, if you don’t know where the bottlenecks lie. So first of all, profile your code using any of the two approaches mentioned below.
3.1. Use stop-watch profiling with <timeit>
It’s the traditional way of profiling using Python’s <timeit> module. It records the time a segment of your code takes for execution. It measures the time elapsed in milliseconds.
import timeit
subStrings=['Sun', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat']
def simpleString(subStrings):
finalString = ''
for part in subStrings:
finalString += part
return finalString
def formatString(subStrings):
finalString = "%s%s%s%s%s%s%s" % (subStrings[0], subStrings[1],
subStrings[2], subStrings[3],
subStrings[4], subStrings[5],
subStrings[6])
return finalString
def joinString(subStrings):
return ''.join(subStrings)
print('joinString() Time : ' + str(timeit.timeit('joinString(subStrings)', setup='from __main__ import joinString, subStrings')))
print('formatString() Time : '+ str(timeit.timeit('formatString(subStrings)', setup='from __main__ import formatString, subStrings')))
print('simpleString() Time : ' + str(timeit.timeit('simpleString(subStrings)', setup='from __main__ import simpleString, subStrings')))joinString() Time : 0.23636290000000001 formatString() Time : 0.711244 simpleString() Time : 0.6721448
The above example demonstrates that the join method is a bit more efficient than the others.
3.2. Use advanced profiling with <cProfile>
It’s since Python 2.5 that cProfile is a part of the Python package. It brings a nice set of profiling features to isolate bottlenecks in the code. You can tie it in many ways with your code. Like, wrap a function inside its run method to measure the performance. Or, run the whole script from the command line while activating cProfile as an argument with the help of Python’s “-m” option.
Here, we are showing some basic examples, so that you can learn how to use it.
3.2.1. Example(1) – Using cProfile in Python
import cProfile
cProfile.run('10*10') 3 function calls in 0.000 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 {built-in method builtins.exec}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}Looking at the results, you can investigate the areas for improvement. Even more useful, we can attach the cProfile while running a script.
3.2.2. Example(2) – Using cProfile in Python
$ python -m cProfile -s cumtime test1.py
3 function calls in 0.000 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 {built-in method builtins.exec}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Prof
iler' objects}
303 function calls (302 primitive calls) in 0.005 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
2/1 0.000 0.000 0.005 0.005 {built-in method builtins.exec}
1 0.000 0.000 0.005 0.005 test1.py:1(<module>)
1 0.000 0.000 0.004 0.004 cProfile.py:15(run)
1 0.000 0.000 0.004 0.004 profile.py:52(run)
1 0.000 0.000 0.004 0.004 cProfile.py:92(run)
1 0.000 0.000 0.004 0.004 cProfile.py:97(runctx)
1 0.004 0.004 0.004 0.004 {method 'enable' of '_lsprof.Profi
ler' objects}
1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap>:966(_find_and_load)
1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap>:939(_find_and_load_unlocked)
1 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:879(_find_spec)
1 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:1133(find_spec)
1 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:1101(_get_spec)
4 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:1215(find_spec)
1 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:659(_load_unlocked)
1 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:659(exec_module)
1 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:729(get_code)
6 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:68(_path_stat)
6 0.000 0.000 0.000 0.000 {built-in method nt.stat}
[...]3.2.3. How to interpret cProfile results?
It’s even more important to find the culprit from the profiling output. You can make a decision only if you know the key elements constituting the cProfile report.
1. <ncalls>: It is the number of calls made.
2. <tottime>: It is the aggregate time spent in the given function.
3. <percall>: Represents the quotient of <tottime> divided by <ncalls>.
4. <cumtime>: The cumulative time in executing functions and their subfunctions.
5. <percall>: Signifies the quotient of <cumtime> divided by primitive calls.
6. <filename_lineno(function)>: Point of action in a program. It could be a line no. or a function at some place in a file.
Now, you have all elements of the profiling report under check. So you can go on hunting the possible sections of your program creating bottlenecks in code.
First of all, start checking the <tottime> and <cumtime> which matters the most. The <ncalls> could also be relevant at times. For the rest of the items, you need to practice it yourself.
4. Using generators and keys for sorting
Generators are a great tool for memory optimization. They facilitate the creation of functions that can return one item (the iterator) at a time instead of returning all at once. A good example is when you’re creating a huge list of numerals and summing them together.
Also, while sorting items in a list, you should use keys and the default <sort()> method to the extent possible. In the below example, check that we are sorting the list as per the index selected as part of the key argument. The same approach, you can use with strings.
import operator
test = [(11, 52, 83), (61, 20, 40), (93, 72, 51)]
print("Before sorting:", test)
test.sort(key=operator.itemgetter(0))
print("After sorting[1]: ", test)
test.sort(key=operator.itemgetter(1))
print("After sorting[2]: ", test)
test.sort(key=operator.itemgetter(2))
print("After sorting[3]: ", test)Before sorting: [(11, 52, 83), (61, 20, 40), (93, 72, 51)] After sorting[1]: [(11, 52, 83), (61, 20, 40), (93, 72, 51)] After sorting[2]: [(61, 20, 40), (11, 52, 83), (93, 72, 51)] After sorting[3]: [(61, 20, 40), (93, 72, 51), (11, 52, 83)]
5. Optimizing loops
Most programming languages stress the need to optimize loops. In Python, we do have a way of turning loops to perform faster. Consider a method that programmers often miss preventing the use of dots within a loop.
In Python, you’ll see a couple of building blocks that support looping. Out of these few, the use of the “for” loop is prevalent. While you might be fond of using loops, they need more CPU cycles. The Python engine spends substantial effort in interpreting the for-loop construct. Hence, it’s always preferable to replace them with built-in constructs like Maps.
Next, the level of code optimization also depends on your knowledge of Python’s built-in features. In the below examples, we’ll try to explain how different constructs can help in optimizing loops.
5.1. Illustrations for optimizing a for loop in Python
Example-1
Let’s consider a function that updates the list of zip codes, strips the trailing spaces, and uses a for loop.
newZipcodes = []
for zipcode in oldZipcodes:
newZipcodes.append(zipcode.strip())Example-2
Now, see how you can translate the above into a single line using the map object. It’ll also be more cost-efficient now.
newZipcodes = map(str.strip, oldZipcodes)
Example-3
We can even use the list comprehensions to make the syntax a bit more linear.
Zipcodes += [iter.strip() for iter in newZipcodes]
Example-4
And lastly, the fastest approach would be to convert the for loop into a generator expression.
itertools.chain(Zipcodes, (iter.strip() for iter in newZipcodes))
5.2. Let’s decode what have we optimized.
As explained above, using generator expression is the fastest way to optimize the for loop in the above use case (and in general). We’ve clubbed the code of four examples so that you can also see the performance gains attained in each approach.
import timeit
import itertools
Zipcodes = ['121212','232323','434334']
newZipcodes = [' 131313 ',' 242424 ',' 212121 ',' 323232','342312 ',' 565656 ']
def updateZips(newZipcodes, Zipcodes):
for zipcode in newZipcodes:
Zipcodes.append(zipcode.strip())
def updateZipsWithMap(newZipcodes, Zipcodes):
Zipcodes += map(str.strip, newZipcodes)
def updateZipsWithListCom(newZipcodes, Zipcodes):
Zipcodes += [iter.strip() for iter in newZipcodes]
def updateZipsWithGenExp(newZipcodes, Zipcodes):
return itertools.chain(Zipcodes, (iter.strip() for iter in newZipcodes))
print('updateZips() Time : ' + str(timeit.timeit('updateZips(newZipcodes, Zipcodes)', setup='from __main__ import updateZips, newZipcodes, Zipcodes')))
Zipcodes = ['121212','232323','434334']
print('updateZipsWithMap() Time : ' + str(timeit.timeit('updateZipsWithMap(newZipcodes, Zipcodes)', setup='from __main__ import updateZipsWithMap, newZipcodes, Zipcodes')))
Zipcodes = ['121212','232323','434334']
print('updateZipsWithListCom() Time : ' + str(timeit.timeit('updateZipsWithListCom(newZipcodes, Zipcodes)', setup='from __main__ import updateZipsWithListCom, newZipcodes, Zipcodes')))
Zipcodes = ['121212','232323','434334']
print('updateZipsWithGenExp() Time : ' + str(timeit.timeit('updateZipsWithGenExp(newZipcodes, Zipcodes)', setup='from __main__ import updateZipsWithGenExp, newZipcodes, Zipcodes')))updateZips() Time : 1.525283 updateZipsWithMap() Time : 1.4145331 updateZipsWithListCom() Time : 1.4271637 updateZipsWithGenExp() Time : 0.6092696999999996
6. Use Set operations
Python uses hash tables to manage sets. Whenever we add an element to a set, the Python interpreter determines its position in the memory allocated for the set using the hash of the target element.
Since Python automatically resizes the hash table, the speed can be constant (O(1)) no matter the size of the set. That’s what makes the set operations execute faster.
In Python, set operations include union, intersection, and difference. So you can try using them in your code where they can fit. These are usually faster than iterating over the lists.
Syntax Operation Description ------ --------- ----------- set(l1)|set(l2) Union Set with all l1 and l2 items. set(l1)&set(l2) Intersection Set with commmon l1 and l2 items. set(l1)-set(l2) Difference Set with l1 items not in l2.
7. Avoid using globals
It’s not limited to Python, almost all languages disapprove of the excessive or unplanned use of globals. The reason behind this is that they could have hidden/non-obvious side effects leading to the Spaghetti code. Moreover, Python is really slow at accessing external variables.
However, it permits the limited use of global variables. You can declare an external variable using the global keyword. Also, make a local copy before using them inside loops.
8. Using external libraries/packages
Some Python libraries have a “C” equivalent with the same features as the original library. Being written in “C” makes them perform faster. For example, try using cPickle instead of using pickle.
Next, you can use <Cython> which is an optimizing static compiler for both the Python. It’s a superset of Python and brings support for C functions and types. It instructs the compiler to produce fast and efficient code.
You can also consider using the PyPy package. It includes a JIT (Just-in-time) compiler which makes Python code run blazingly fast. You can even tweak it to provide an extra processing boost.
9. Use built-in operators
Python is an interpreted language based on high-level abstractions. So you should use the built-ins wherever possible. It’ll make your code more efficient because the built-ins are pre-compiled and fast. Whereas the lengthy iterations which include interpreted steps get very slow.
Similarly, prefer using built-in features like the map which add significant improvements in speed.
10. Limit method lookup in a loop
When working in a loop, you should cache a method call instead of calling it on the object. Otherwise, the method lookups are expensive.
Consider the following example.
>>> for it in xrange(10000): >>> myLib.findMe(it)
>>> findMe = myLib.findMe >>> for it in xrange(10000): >>> findMe(it)
11. Optimizing using strings
String concatenation is slow, don’t ever do that inside a loop. Instead, use Python’s join method. Or, use the formatting feature to form a unified string.
RegEx operations in Python are fast as they get pushed back to C code. However, in some cases, basic string methods like <isalpha()/isdigit()/startswith()/endswith()> works better.
Also, you can test different methods using the <timeit> module. It’ll help you determine which method is truly the fastest.
12. Optimizing with the if statement
Like most programming languages allow lazy-if evaluation, so does Python. It means, that if there are joining ‘AND’ conditions, then not all conditions will be tested in case one of them turns false.
1. You can adjust your code to utilize this behavior of Python. For example, if you are searching for a fixed pattern in a list, then you can reduce the scope by adding the following condition.
Add an ‘AND’ condition which becomes false if the size of the target string is less than the length of the pattern.
Also, you can first test a fast condition (if any) like “string should start with an @” or “string should end with a dot.”.
2. You can test a condition <like if done is not None> which is faster than using <if done != None>.
Summary – Python Code Optimization Tips and Tricks
We hope the methods given in this article can help you build faster Python applications. But while applying these tips, keep in mind that only optimize when you’ve established gray areas in your code.
Some of the tips you can directly adopt in your coding practice. Like, the use of profiling methods, they are the ones to give you the right direction and lead to the road of optimization.
Apart from the above tips, you must check your code for quadratic behavior. You should be aware of the time complexity of the different Python constructs like the list, set, and collections. Lastly, collect as data as much you can, it’ll help you establish whether what you are doing is right or not.
If somehow the above post “Python Code Optimization Tips and Tricks” would have driven you to write faster and quality code, then don’t mind sharing it with the rest of the world.
If You Are Working On Something That You Really Care About, You Don’t Have To Be Pushed. The Vision Pulls You. – Steve Jobs
All the Best,
TechBeamers






